多终端数据同步的设计与实现
多终端数据同步的设计与实现
文/杜明晶
【关键词】系统架构 数据同步 Thrift
摘要:MySQL 分布式数据库
随着科技的不断发展,人们拥有新兴终端设备的趋势愈发具
有多样性和广泛性,而随着生活节奏的加快,人们在多终端设备
中记录管理事务的需求也在逐渐增长,但由于目前网络覆盖面积
的局限性和网络的不稳定性,终端设备并不能时刻保持着连接到
网络的状态。在连接网络异常的情况下进行操作,就会出现发布
失败、各终端同步异常、分享失败等问题。针对以上问题,本文
提出并设计了一款系统架构,该系统架构具有远程同步和其他用
户分享的功能,能够使人们在终端设备网络未连接时进行无差别
操作,保持多终端数据的一致性。
1 背景
随着信息产业的不断发展,人们在生活中往往使用着手机、PAD、笔记本电脑等多款
智能产品。在生活节奏日益加快的今天,用户经常对其拥有的单一终端设备进行记录、处理
等操作,并在网络连接状态下能够进行分享、同步至多终端进行后续操作。针对网络连接失
败有可能导致的问题,可以用以下思路解决:在网络连接成功时记录下操作,而在网络连接
成功时上传服务器。
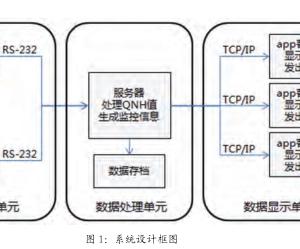
2 应用系统设计
本文将多终端数据同步设计应用在 C/S 模式下的系统中,该系统拥有安卓、IOS、WP8
和 windows 四个版本,服务器端是采用经典的LAMP 组合,通信方面则采用了 Thrift 架构。
以下对系统框架中重要组件进行详细说明。
2.1 Thrift框架
Apache Thrift 是 Facebook 公司开发的远程服务调用框架,它采用接口描述语言定义并
创建服务,支持可扩展的跨语言服务开发,所包含的代码生成引擎可以在 C++,Java,
Python,PHP 等多种语言中创建高效的、无缝的服务,其传输数据采用二进制格式,与相对
体积庞大且传输效率低的 XML 相比,Thrift框架的优势非常明显,而相比于 JSON,Thrift
则更加成熟完善,具有更高的效率。
2.2 终端设计
2.2.1 终端的操作时间轴表
每个终端设备对每个用户创建一个操作时间轴表,以记录在一段时间范围内,该用户
在该终端上对本地数据库进行的各种操作,包括增删改。当用户同步成功之后,服务器会返
回给设备一个全新的时间戳。同步时间戳由服务器统一发放管理维护,保证了终端更新的可靠性。
2.2.2 简化同步信息算法
因为用户离线操作的很多内容没有必要全部与服务器同步,如用户创建一个事务不久
之后将其删除,再进行同步,服务器就没有必要再去接受与该事务有关的任何信息,为了节
省传输成本,在终端上做一个优化算法使客户端同步给服务器的信息尽可能的少。这部分一
般由本地数据库的触发器完成,如果本地数据库不支持触发器,由程序完成。
2.2.3 全球唯一 ID
所有的数据库,无论是本地数据库还是服务器数据库,都不使用数据库自身的 ID,
而用一个接口专门生成全球唯一 ID,随数据信息一同写入数据库,这不仅确保前后台数据
同步的定位准确,更为以后的多库扩展做好了准备。
2.3 服务器设计
2.3.1 MySQL 服务器
采用单点master的分布式MySQL服务器,实现读写分离。
2.3.1.1 复制机制
目前主流的两种复制方式是,基于记录的复制 (Row-Based Replication) 与基于语句的
复制 (Statement-Based Replication)。因为,本系统中很少出现一个 SQL 语句能批量操作大
量记录的情况, 体现不了基于语句复制的优势,又因为数据库中使用了触发器,因此选择使用
基于记录的复制。
2.3.1.2 存储引擎
MySQL 常用的存储引擎有 MyISAM 与InnoDB,因为数据更新时,有大量的写入操
作, 同一时间不能排除没有读取操作的可能性。为了调高读取效率,我们选择 InnoDB 存储引
擎,其在修改内容时采用的是行锁机制,避免了 MyISAM 中表锁所导致的整个数据表无法读取的情况。
2.3.1.3 分表
数据量巨大,分表是必须的。系统主要采用的是水平分表。大量信息的访问率对时间
的依赖性很强,因此大部分的分表是依据时间进行的。当然还有一些是根据用户 ID 进行分
表的,如私信表等。
2.3.1.4 索引
使用了大量索引,因为对时间依赖性强,大部分组合索引都以时间戳作为第一索引。
2.3.2 同步机制
2.3.2.1 同步策略
一次同步的大体流程如下:
每次终端同步时,除了会发送一些认证信息之外,还有在一段时期内的操作,此时服
务器在认证成功之后,采取优先写入的方式,即将客户端的信息先写进服务器(写入的内容
如与其他用户有关,就会在其相关用户相应的时间轴表中插入一行操作记录,也属于一种用
空间换取读取效率的方式)。写入完成后,再将比这段同步时期略久一点的时间范围内接收
到的有关该用户在该终端上的操作变化返回,同变化内容一起返回的还有一个比此次终点时
间戳略大的值,此值作为下次同步的起点。接着介绍下,一次同步,同步起点与终
点时间的概念。
起点:客户端上会有一个上次同步成功之后返回的时间戳,以此为起点。
终点:服务器接收到同步请求时服务器的时间戳为终点。
2.3.2.2 服务器操作时间轴表
服务器也有一个操作时间轴表,此表以时间戳为基准存储每个用户使用不同终端同步的
操作。仅包含,用户 ID,设备 ID,操作 ID,操作表 ID,行 ID 和时间戳字段,不含有任何
内容字段,以尽量小的空间换取读取速度。此表以用户 ID 和时间戳作为组合索引。每次读
取一个用户在某一设备上,从起点到比此次终点略大一点时间范围内的所有操作。通过算法
优化整合出对于各记录所做操作的最终结果,之后进行读取,并返回给客户端。
3 结束语
对面向可离线多终端的前后台数据同步进行了分析,总结了一种架构设计,并给出了
许多细节及难点上的解决方法。随着大数据时代的到来,此种架构也将
受到大数据请求的冲击,其中仍有许多需要改进和扩展的地方。例如:MySQL 服务器可以
扩展成为多点 master 的;对 apache 服务器也进行负载均衡;对冲突策略和优化算法进行进
一步改进等。
参考文献
[1] 李华植 . 海量数据库解决方案 [M]. 郑保卫 , 盖国强 , 译 . 北京 : 电子工业出版社,2011:332-339.
[2] 姜 承 尧 .MySQL 技 术 内 幕 :InnoDB 存 储引 擎 [M]. 北 京 : 电 子 工 业 出 版 社,2011:114-115.
作者单位成都理工大学信息科学与技术学院 1 四川省成都市 610059